
浏览器的渲染流程(1)
浏览器渲染整体流程
浏览器,作为用户浏览网页最基本的一个入口,我们似乎认为在地址栏输入 URL 后网页自动就出来了。殊不知在用户输入网页地址,敲下回车的那一刻,浏览器背后做了诸多的事情。
去除 DNS 查找等这些细枝末节的工作,整个大的部分可以分为两个,那就是网络和渲染。

首先,浏览器的网络线程会发送 http 请求,和服务器之间进行通信,之后将拿到的 html 封装成一个渲染任务,并将其传递给渲染主线程的消息队列。在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
网络线程和服务器之间通信的过程并非本节课咱们要讨论的,这里要研究的主要内容,是浏览器的渲染进程如何将一个密密麻麻的 html 字符串渲染成最终页面的。
我们先来看一下整体流程,整个渲染流程分为多个阶段,分别是: HTML 解析、样式计算、布局、分层、生成绘制指令、分块、光栅化、绘制:
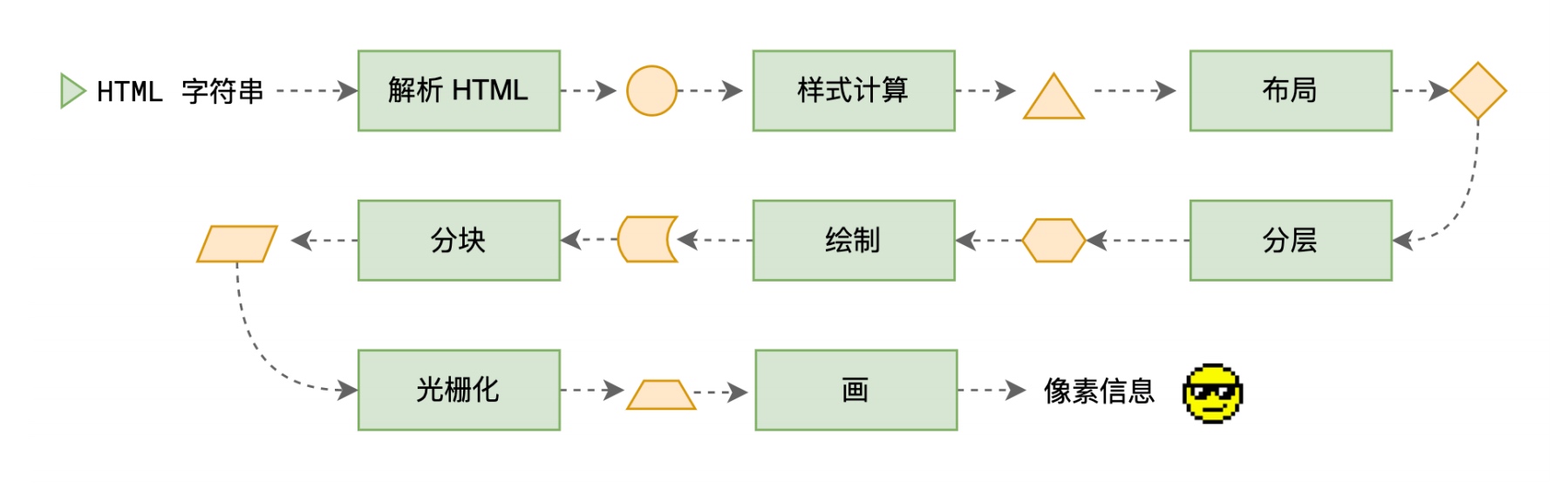
每个阶段都有明确的输入输出,上一个阶段的输出会成为下一个阶段的输入。
这样,整个渲染流程就形成了一套组织严密的生产流水线。
接下来,咱们就一起来看一下每一个阶段的各个流程究竟是在干什么。
解析 HTML
首先第一步就是解析 html,生成 DOM 树。
当我们打开一个网页时,浏览器都会去请求对应的 HTML 文件。虽然平时我们写代码时都会分为 HTML、CSS、JS 文件,也就是字符串,但是计算机硬件是不理解这些字符串的,所以在网络中传输的内容其实都是 0 和 1 这些字节数据。
当浏览器接收到这些字节数据以后,它会将这些字节数据转换为字符串,也就是我们写的代码。

当数据转换为字符串以后,浏览器会先将这些字符串通过词法分析转换为标记( token ),这一过程在词法分析中叫做标记化( tokenization )。
为什么需要标记化呢?原因很简单,现在浏览器虽然将字节数据转为了字符串,但是此时的字符串就如何一篇标题段落全部写在一行的文章一样,浏览器此时仍然是不能理解的。
例如:
<!DOCTYPE html><html lang="en"><head><title>Document</title></head><body><p>this is a test</p></body></html>
因此现在所做的标记化,本质就是要将这长长的字符串分拆成一块块,并给这些内容打上标记,便于理解这些最小单位的代码是什么意思。
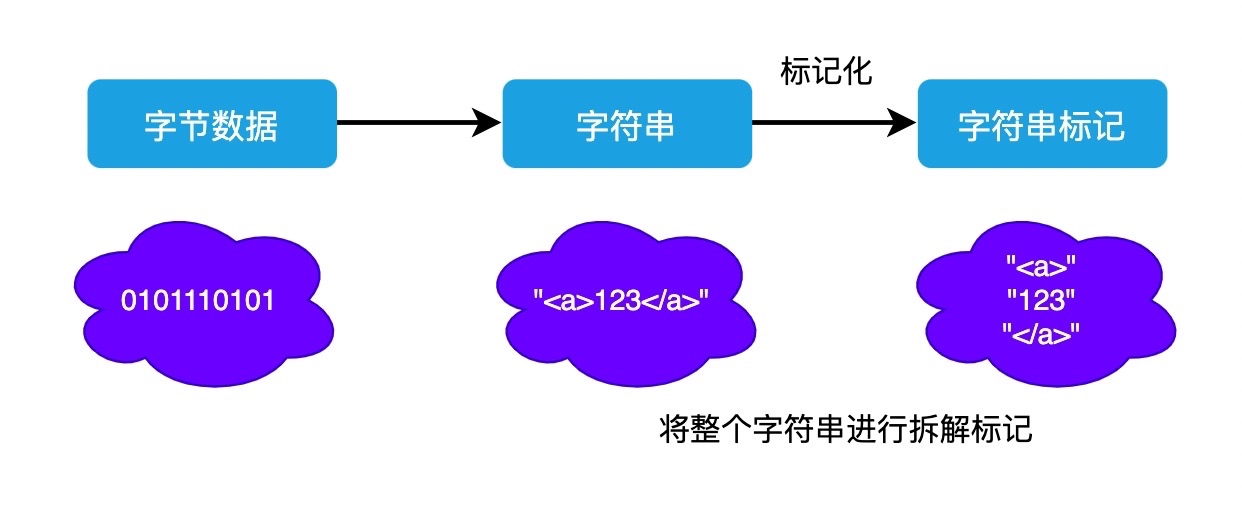
将整个字符串进行了标记化之后,就能够在此基础上构建出对应的 DOM 树出来。
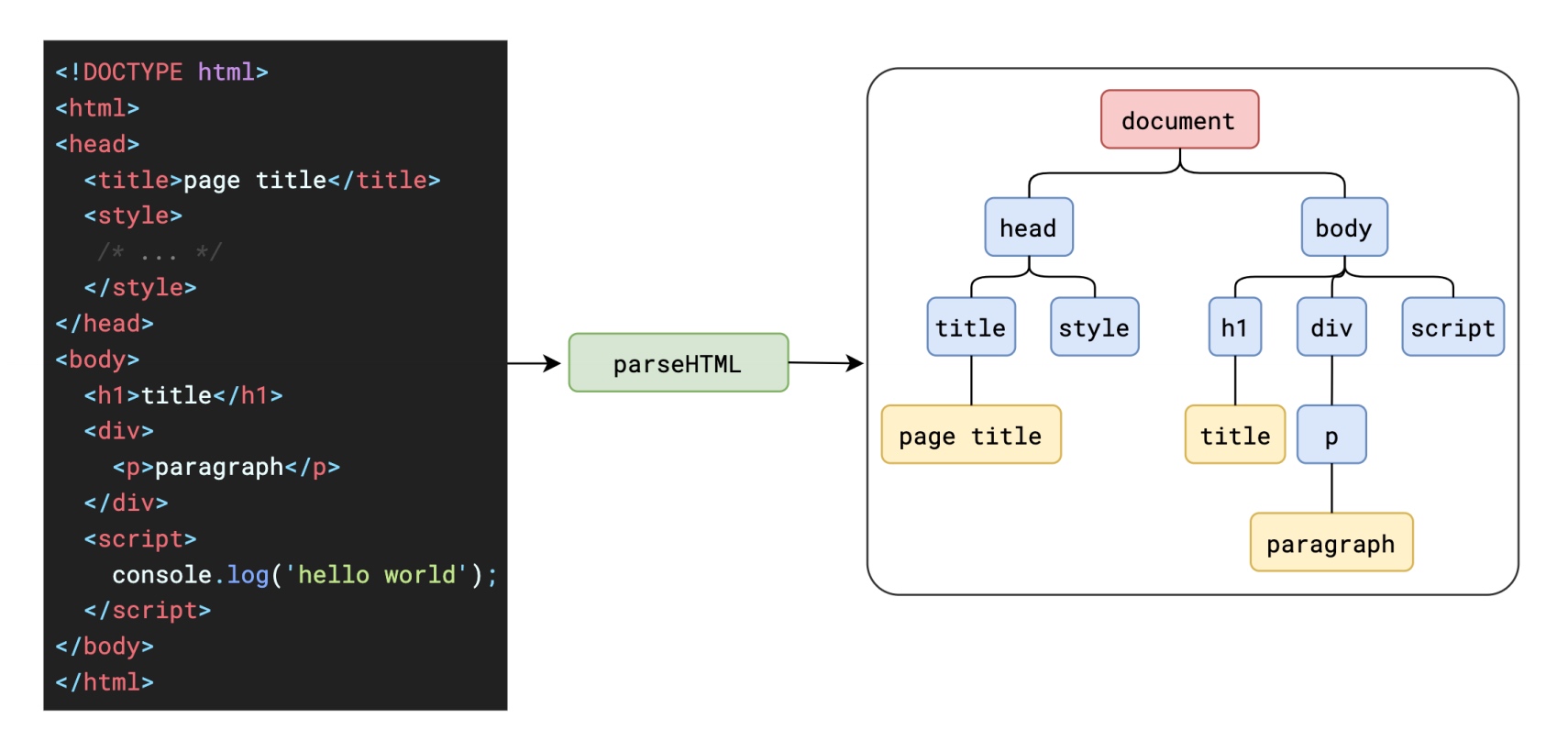
上面的步骤,我们就称之为解析 HTML。整个流程如下图:
在解析 HTML 的过程中,我们可以能会遇到诸如 style、link 这些标签,聪明的你应该已经想到了,这是和我们网页样式相关的内容。此时就会涉及到 CSS 的解析。
为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载 HTML 中的外部 CSS 文件和外部的 JS 文件。
如果主线程解析到 link 位置,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。
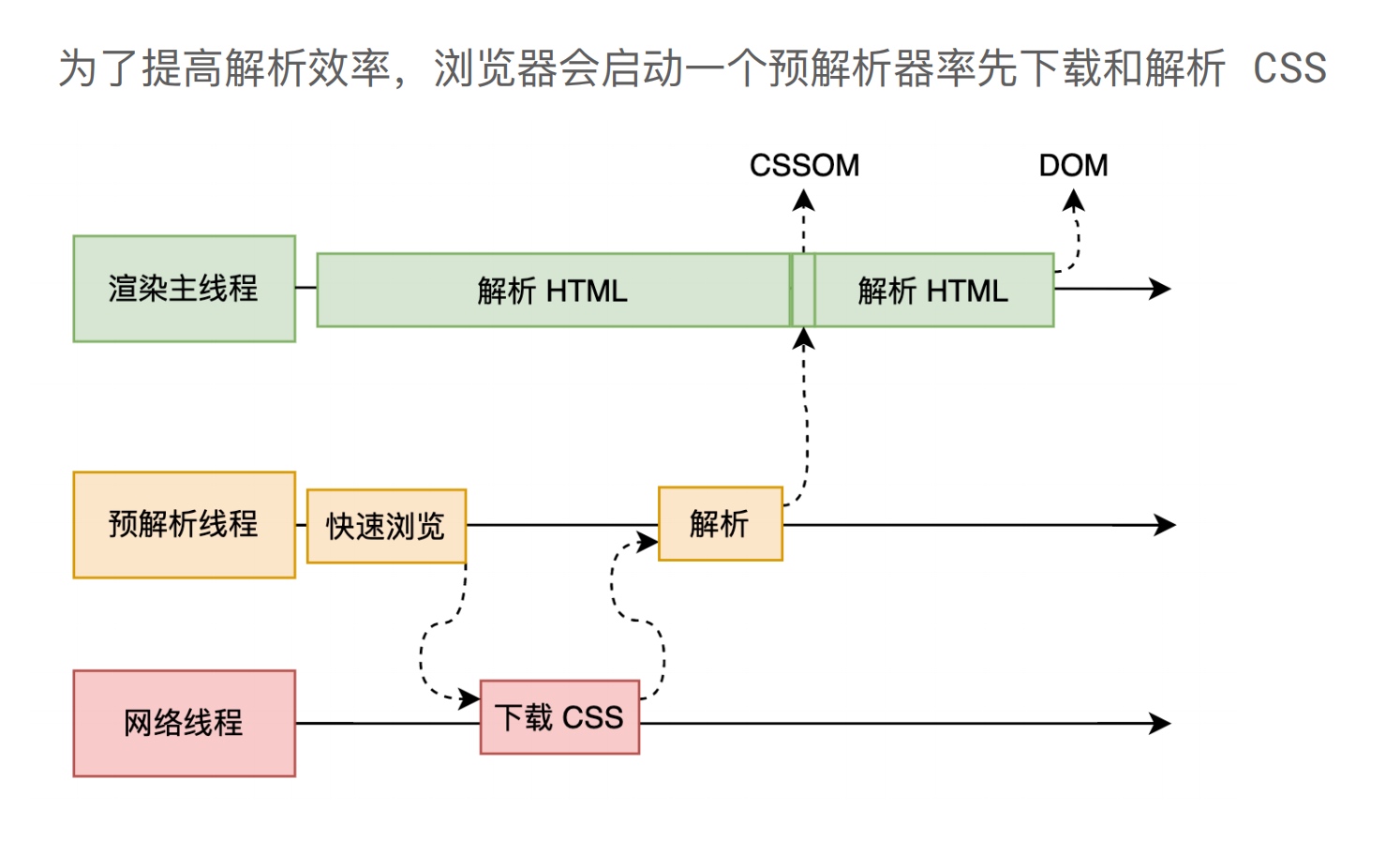
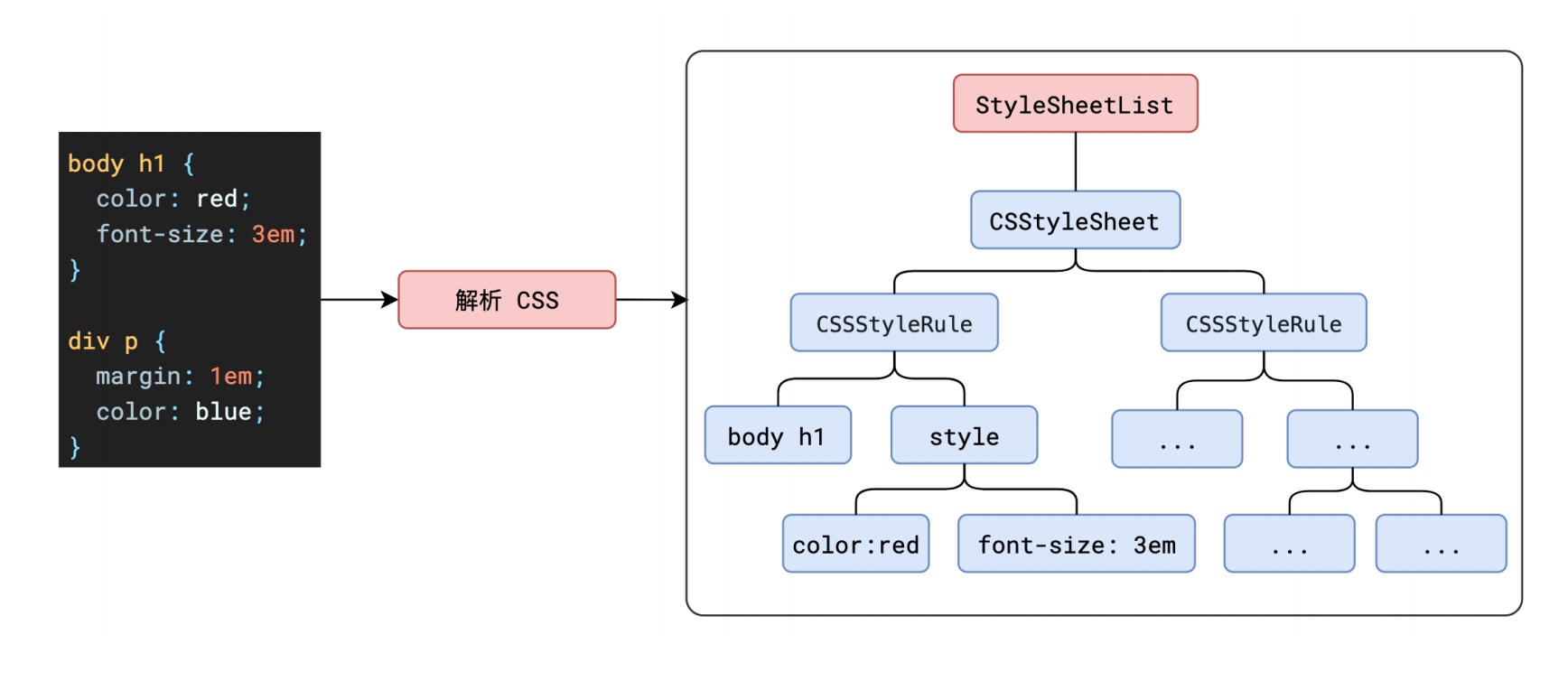
最终,CSS 的解析在经历了从字节数据、字符串、标记化后,最终也会形成一颗 CSSOM 树。
上面也有提到,预解析线程除了下载外部 CSS 文件以外,还会下载外部 JS 文件,那么这里同学们自然也会好奇针对 JS 代码浏览器是如何处理的?
如果主线程解析到 script 位置,会停止解析 HTML,转而等待 JS 文件下载好,并将全局代码解析执行完成后,才能继续解析 HTML。
这是因为 JS 代码的执行过程可能会修改当前的 DOM 树,所以 DOM 树的生成必须暂停。这就是 JS 会阻塞 HTML 解析的根本原因。
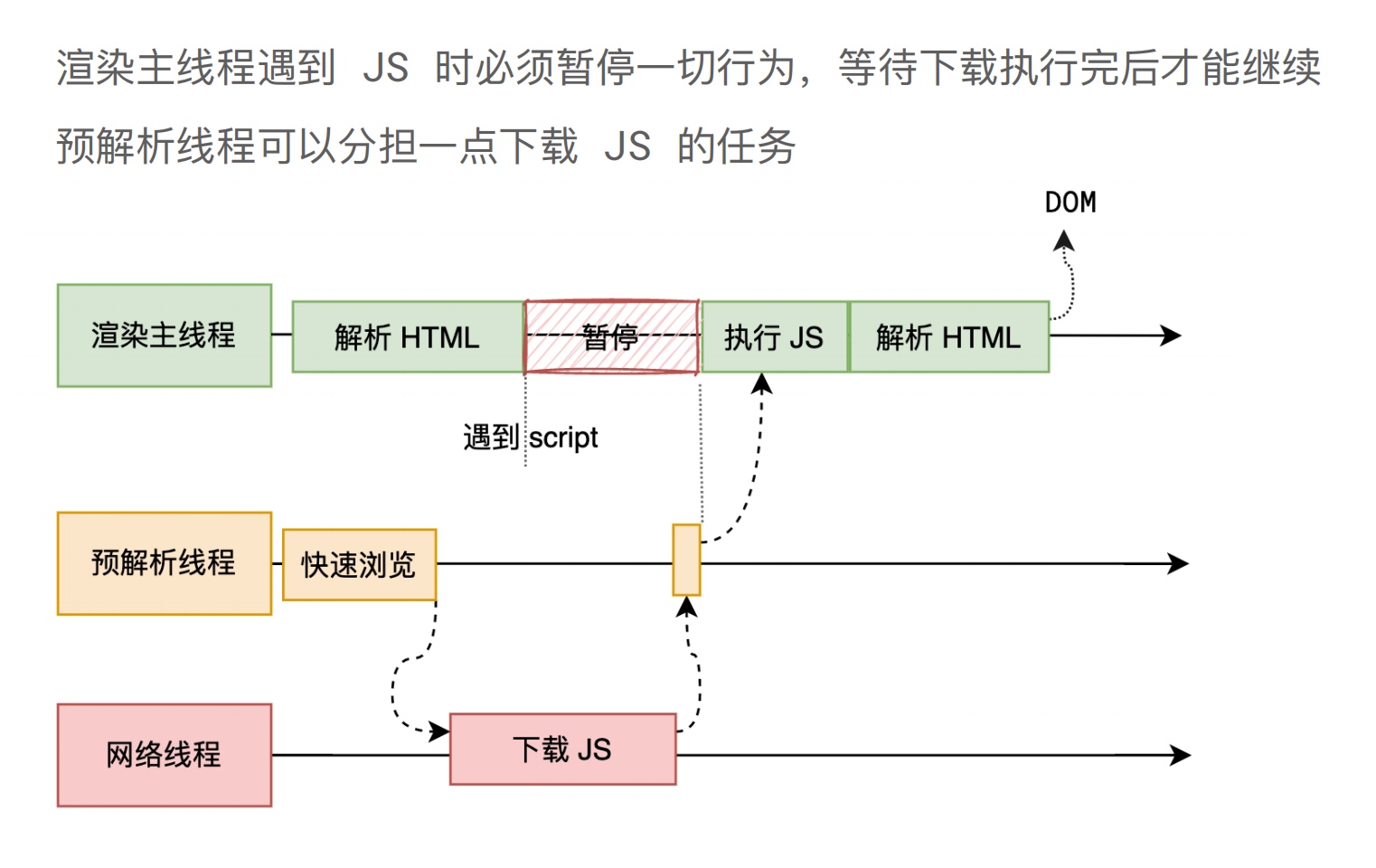
因此,如果你想首屏渲染的越快,就越不应该在最前面就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。
<html>
<head>
...
</head>
<body>
<p></p>
<script src="..."></script>
</body>
</html>
当然在现代浏览器中,为我们提供了新的方式来避免 JS 代码阻塞渲染的情况:
- async
- defer
- prefetch
- preload
关于这几种方式的区别,不是我们这里需要关注的点,直接先忽略。
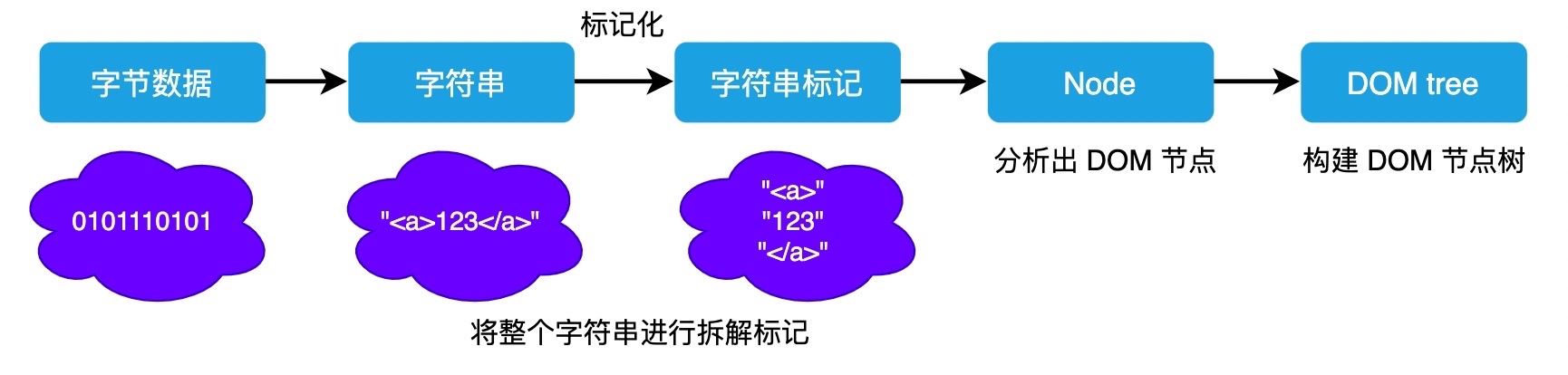
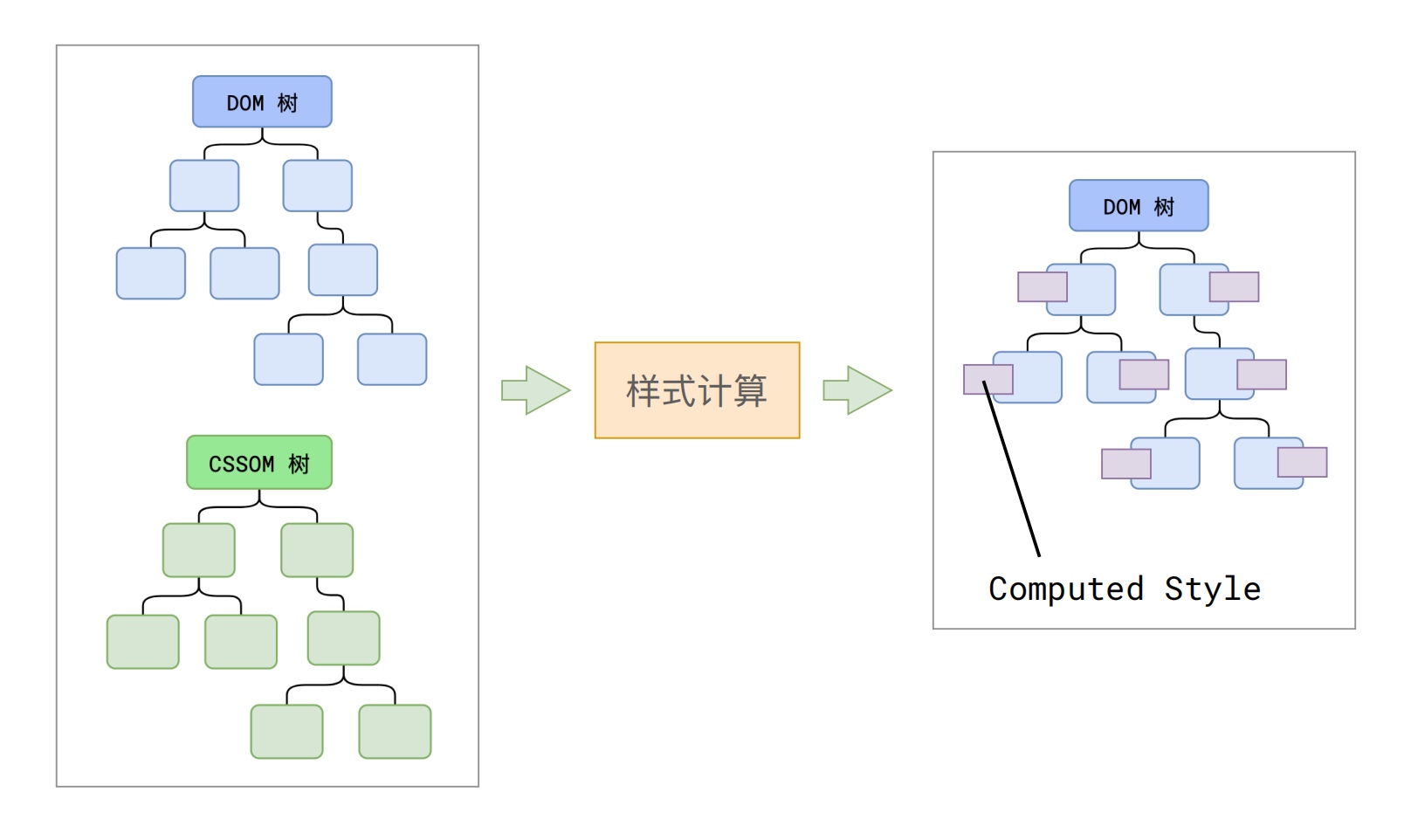
最后总结一下此阶段的成果,第一步完成后,会得到 DOM 树和 CSSOM 树,浏览器的默认样式、内部样式、外部样式、行内样式均会包含在 CSSOM 树中。
得到了两棵树,如下图所示:
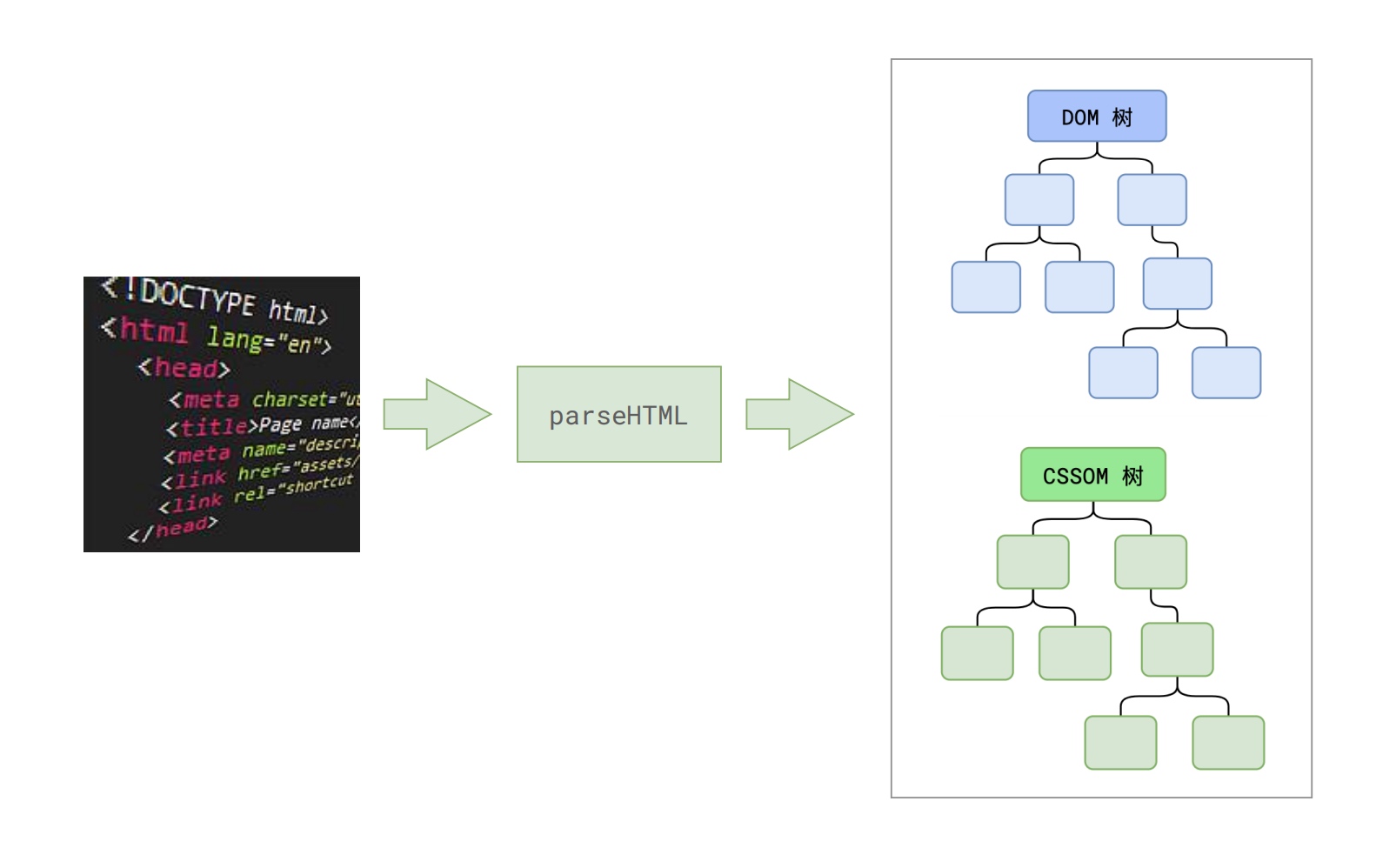
样式计算
接下来进入第二步:样式计算
拥有了 DOM 树我们还不足以知道页面的外貌,因为我们通常会为页面的元素设置一些样式。主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。
在这一过程中,很多预设值会变成绝对值,比如 red 会变成 rgb(255,0,0);相对单位会变成绝对单位,比如 em 会变成 px。
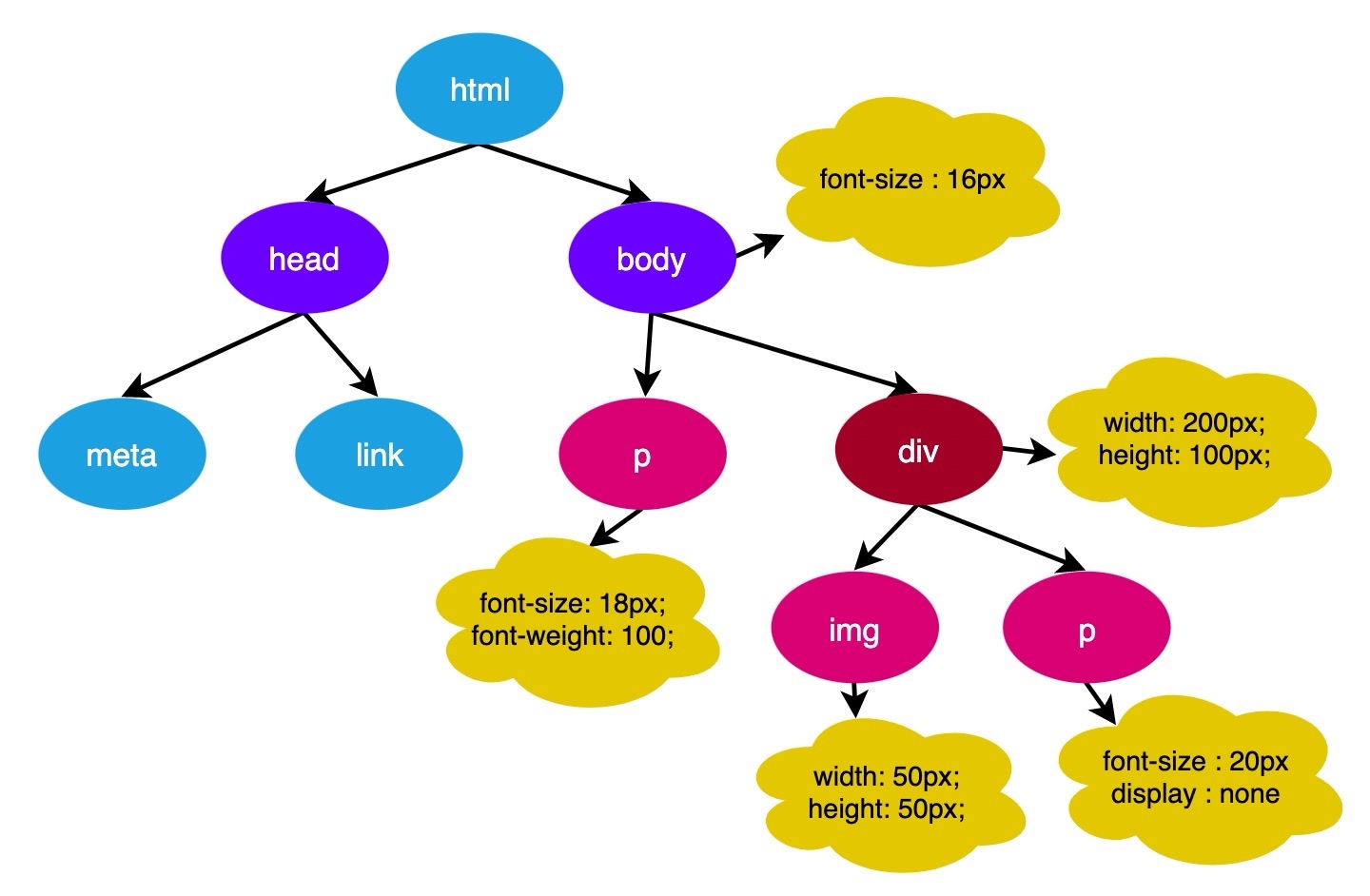
浏览器会确定每一个节点的样式到底是什么,并最终生成一颗样式规则树,这棵树上面记录了每一个 DOM 节点的样式。
另外需要注意的是,这里所指的浏览器确定每一个节点的样式,是指在样式计算时会对所有的 DOM 节点计算出所有的样式属性值。如果开发者在书写样式时,没有写某一项样式,那么大概率会使用其默认值。例如:
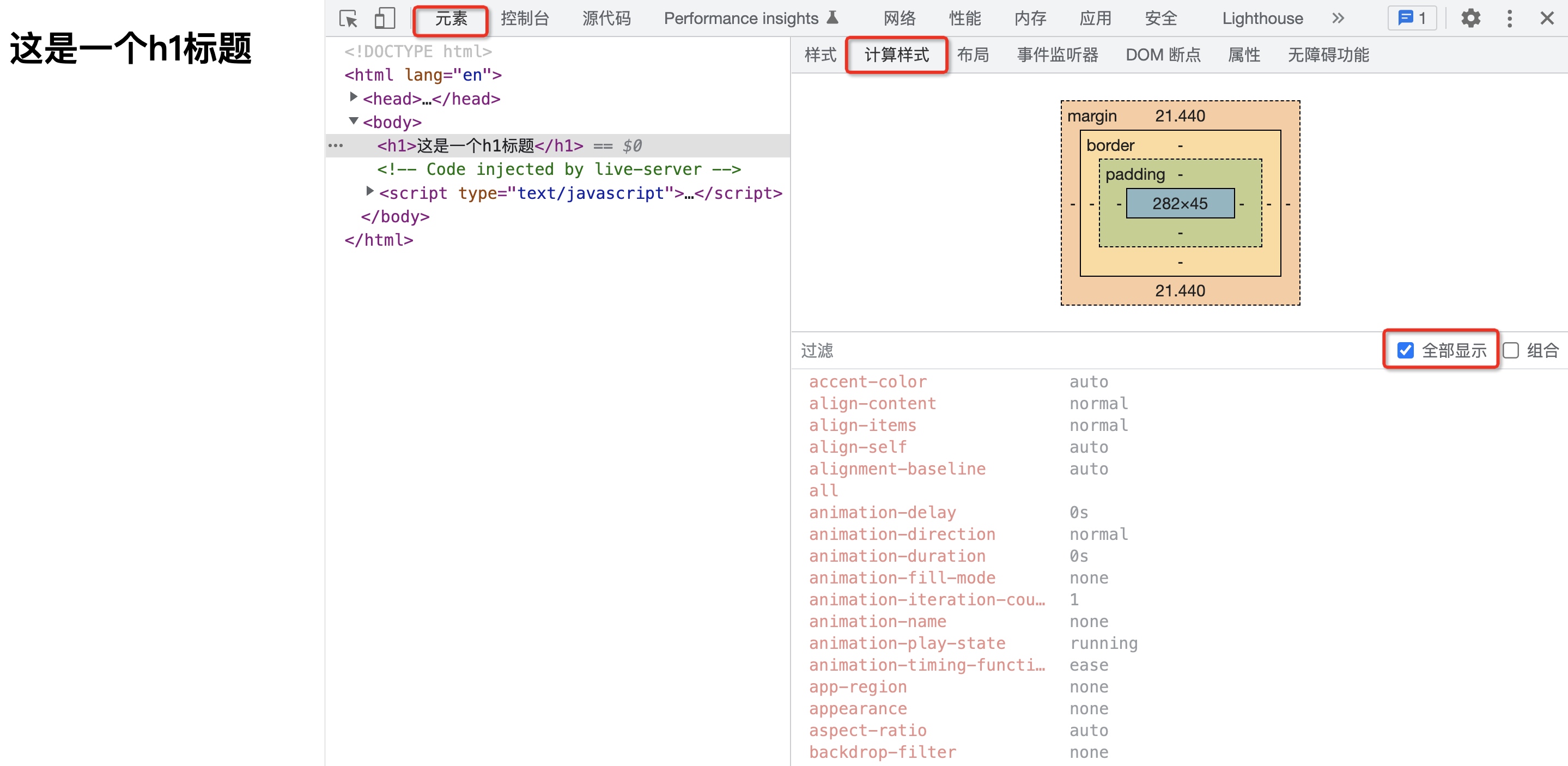
这一步完成后,我们就得到一棵带有样式的 DOM 树。也就是说,经过样式计算后,之前的 DOM 数和 CSSOM 数合并成了一颗带有样式的 DOM 树。
Comments